Zürich, Sun 30 Jun 2024
Devanagari in the Protomaps Basemap with a Positioned Glyph Font for MapLibre
Devanagari is the writing system of South Asian languages including Nepali, Hindi, or Marathi. It is a writing system or script which requires shaping, a process in which Unicode input text is turned into a visual representation based on a given font. However, MapLibre GL JS and MapLibre Native do not support text shaping and therefore are unable to display Devanagari text correctly. There are several other languages and writing systems in countries such as India, Bangladesh, Myanmar, or Cambodia which are not supported by MapLibre and as a consequence, MapLibre is unable to display maps in the native language of over one billion people worldwide.
The positioned glyph font (PGF) approach aims to manage text shaping at tile-generation time and promises to display maps with Devanagari labels in any map renderer that supports the MapLibre styling language, including MapLibre GL JS and MapLibre Native. Here, we will walk through the different aspects of the system and discuss an implementation in the Protomaps Basemap.
This text assumes that you are familiar with text rendering in MapLibre and know the basics of text shaping, both of which you can learn more about here: https://oliverwipfli.ch/about-text-rendering-in-maplibre-2023-10-17/
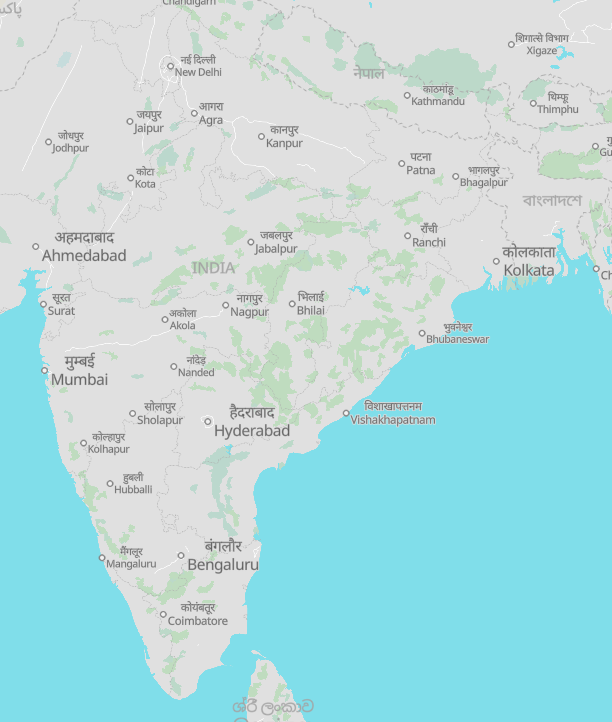
Demo
Map localized to Nepali with fallback to Marathi and Hindi: https://wipfli.github.io/protomaps-pgf-demo/.
Word Corpus
The first step to create a positioned glyph font for Devanagari is to collect a word corpus. The code for this can be found here: https://github.com/wipfli/word-corpus. The word corpus shall contain as many unique words or sequences of characters as possible in the Devanagari Unicode blocks and it should be sourced based on free and open data.
To collect a comprehensive word corpus in Devanagari we extracted strings from the following three open data sources:
- Wikipedia
- Wikidata
- OpenStreetMap
Unsurprisingly, Wikipedia was the largest corpus of the three and contained over 16 million unique words, or better, unique character sequences in the Devanagari script since not all of those are necessarily real words.
Encoding
The next step is to generate an encoding from positioned glyph to Unicode codepoint. The code for this section is available at https://github.com/wipfli/pgf-encoding.
We take the Devanagari word corpus from the previous section and use Noto Sans Devanagari Regular from Google Fonts, which is published under the SIL Open Fonts License, and the open-source text shaping engine HarfBuzz to shape all the strings in the corpus with the Noto font. Shaping the entire corpus with the HarfBuzz CLI command took several days on a single-core machine.
As a result of the shaping, we get glyph vectors for each string which contains positioned glyphs. MapLibre uses 64x lower precision on the positioned glyph advance and offset values than HarfBuzz and we therefore need to convert first the HarfBuzz (HB) positioned glyphs to MapLibre (ML) positioned glyphs.
We then count how many times each MapLibre positioned glyph appears when we shape the entire corpus. The most encountered glyph corresponds to the Unicode character Devanagari Vowel Sign Aa which was counted over 17 million times. The positioned glyphs are ordered by count and allocated to codepoints in the private use area (PUA) in Unicode. This step is what generates the encoding. The PUA has over 6000 codepoints which are never used for regular scripts, and therefore can be thought of as free space in Unicode. Note that MapLibre GL JS and MapLibre Native use PUA codepoints internally for referencing images in text. MapLibre starts by allocating low to high codepoints in the PUA for its custom image handling, and we therefore use high to low allocation for the positioned glyphs to PUA codepoints.
The mapping from positioned glyph to codepoint is somewhat arbitrary. If a different text corpus is used for example, one might get a different ranking of counts and therefore a different encoding. We therefore give each encoding a version. The resulting encoding for the font "NotoSansDevanagari-Regular.ttf" gets version 1 and we store the encoding in a file called "NotoSansDevanagari-Regular-v1.csv".
Glyph Ranges
Now that we have an encoding from positioned glyph to PUA codepoint for NotoSansDevanagari-Regular.ttf, it is time to generate MapLibre glyph ranges. This is done by feeding the ttf font together with the encoding csv to a modified version of maplibre/font-maker. The code can be found here: https://github.com/wipfli/pgf-glyph-ranges
The output of this process is 4 glyph ranges for NotoSansDevanagari-Regular-v1 which are all in the private use area. To turn this into a full fontstack, we combine the PGF ranges with the usual glyph ranges of the pan-unicode fontstack "Noto Sans Regular" using symbolic links, see https://github.com/protomaps/basemaps-assets/tree/main/fonts. The resulting fontstack is called "Noto Sans Devanagari Regular v1".
This step concludes the font generation part. Next, we have to generate vector tiles that use the same encoding.
Vector Tiles
Now that we have a PGF fontstack for Devanagari what remains to be done is to generate vector tiles that reference the same encoding for Devanagari labels. We do this by modifying the Protomaps Basemap, the respective pull request is available here: https://github.com/protomaps/basemaps/pull/265
The Protomaps Basemap uses Planetiler for vector tile
generation. When the program starts, the font file NotoSansDevanagari-Regular.ttf and the encoding
NotoSansDevanagari-Regular-v1.csv are loaded into memory. Then, all strings are segmented into parts that
are purely Devanagari and parts that contain characters of other scripts. The Devanagari segments are then
sent to HarfBuzz via Java's built-in java.awt.Font API for shaping.
The resulting glyph vectors are mapped to MapLibre positioned glyphs, then the encoding is used to map from
positioned glyph to PUA codepoint. Finally, the encoded string is stored in a new vector tile property that
gets prefixed with pmap:pgf:, e.g., pmap:pgf:name contains the encoded version of
the name property.
We store information about the PGF font name and encoding version in the tileset metadata. For example, we
include the font name used to encode Devanagari as
pgf:devanagari:name = NotoSansDevanagari-Regular and the version as
pgf:devanagari:version = 1. This information is important when designing a MapLibre style.json
document because of the strong coupling between the tiles and the fontstack.
Style.json
Let us now have a look how the encoded tiles and the PGF fontstack can be used to make a MapLibre style.json that is localized to Nepali.
Our goal is to have a map where city labels are written in Nepali in the first line, or if Nepali is not available, in any language that uses Devanagari. This is called a language fallback chain and we use Hindi and Marathi as fallback languages here. In the second line, we write the name of the city if the native name is not written using the Devanagari script.
Example Kathmandu
काठमाडौँ
Explanation: Kathmandu is available in Nepali and the osm name uses Devanagari, so we just
write one line.
Example Zürich
ज़्यूरिख़
Zürich
Explanation: The osm name for Zürich is not in Devanagari, so we write it in the second line.
In the first line we write the name:hi for Zürich because Nepali might not be available.
In OpenStreetMap, Nepali names are stored as name:ne. If no Nepali name is present, we can
fallback to Hindi (name:hi) and Marathi (name:mr), since both also use the
Devanagari script. This can be done with the coalesce expression in
MapLibre.
While one can guess what script is used for specific language tags such as name:ne (Devanagari)
or name:fr (Latin), it is unclear what script is in the name tag since it can be
any language. We therefore store the script used in the name tag in pmap:script,
e.g.., if name contains a Devanagari string, we have pmap:script = Devanagari. If
the name tag contains Latin only, we omit the pmap:script to save space.
We use the text-font option in the format expression in MapLibre to
define which fontstack should be used.
You can have a look at the full demo style.json localized to Nepali here.
Discussion
The advantage of the positioned glyph font approach is that for the first time we are able to show Devanagari map labels with stock MapLibre GL JS and MapLibre Native. No modification was needed in the client rendering engines and accordingly, the binary size of those did not increase.
The disadvantage is that the font has to be decided on at tile-generation time and one cannot use arbitrary fonts with the files - there is strong coupling between the tiles and the fontstack.
Outlook
More localized styles should be created for Nepali, Hindi, Marathi, but also for languages such as English and other already supported languages. These styles should make use of the now introduced PGF encoding and should be distributed via the Protomaps Basemap.
We can also add more writing systems for languages in India, Bangladesh, Myanmar, and Cambodia. In total there should be at least 10 more widely used scripts that fall within the category of unsupported scripts in MapLibre.
Finally, one might think of creating a MapLibre GL JS plugin which runs the HarfBuzz wasm port in the client. This would allow client-side shaping and would make it possible to use the PGF approach with existing tilesets.
This work was supported by NLnet grant number 2023-08-362 of the NGI0 Core Fund with financial support from the European Commission's Next Generation Internet program.